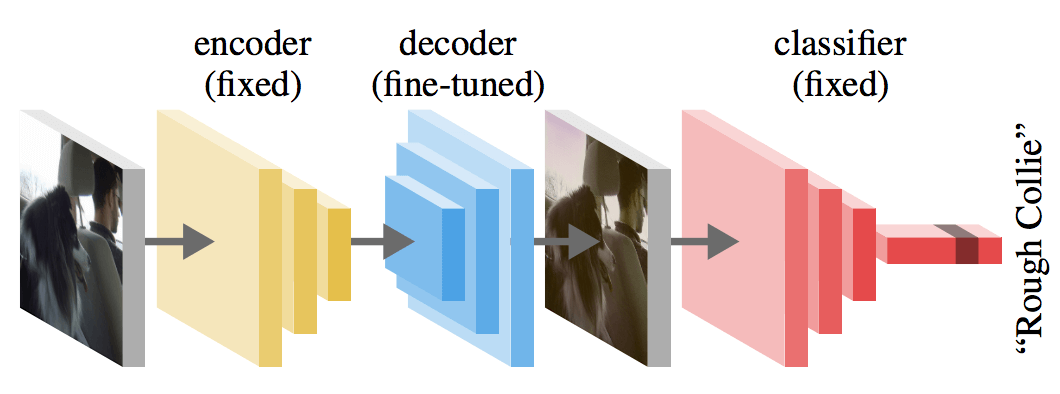
We propose a novel way to measure and understand convolutional neural networks by quantifying the amount of input signal they let in. To do this, an autoencoder (AE) was fine-tuned on gradients from a pre-trained classifier with fixed parameters. We compared the reconstructed samples from AEs that were fine-tuned on a set of image classifiers (AlexNet, VGG16, ResNet-50, and Inception v3) and found substantial differences. The AE learns which aspects of the input space to preserve and which ones to ignore, based on the information encoded in the backpropagated gradients. Measuring the changes in accuracy when the signal of one classifier is used by a second one, a relation of total order emerges. This order depends directly on each classifier’s input signal but it does not correlate with classification accuracy or network size. Further evidence of this phenomenon is provided by measuring the normalized mutual information between original images and auto-encoded reconstructions from different fine-tuned AEs. These findings break new ground in the area of neural network understanding, opening a new way to reason, debug, and interpret their results. We present four concrete examples in the literature where observations can now be explained in terms of the input signal that a model uses.






@InProceedings{palaciofolz2018finetunedecoders,
author = {Palacio Sebastian, Folz Joachim, Hees Joern, Raue Federico, Borth Damian, Dengel Andreas},
title = {What do Deep Networks Like to See},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2018}
}
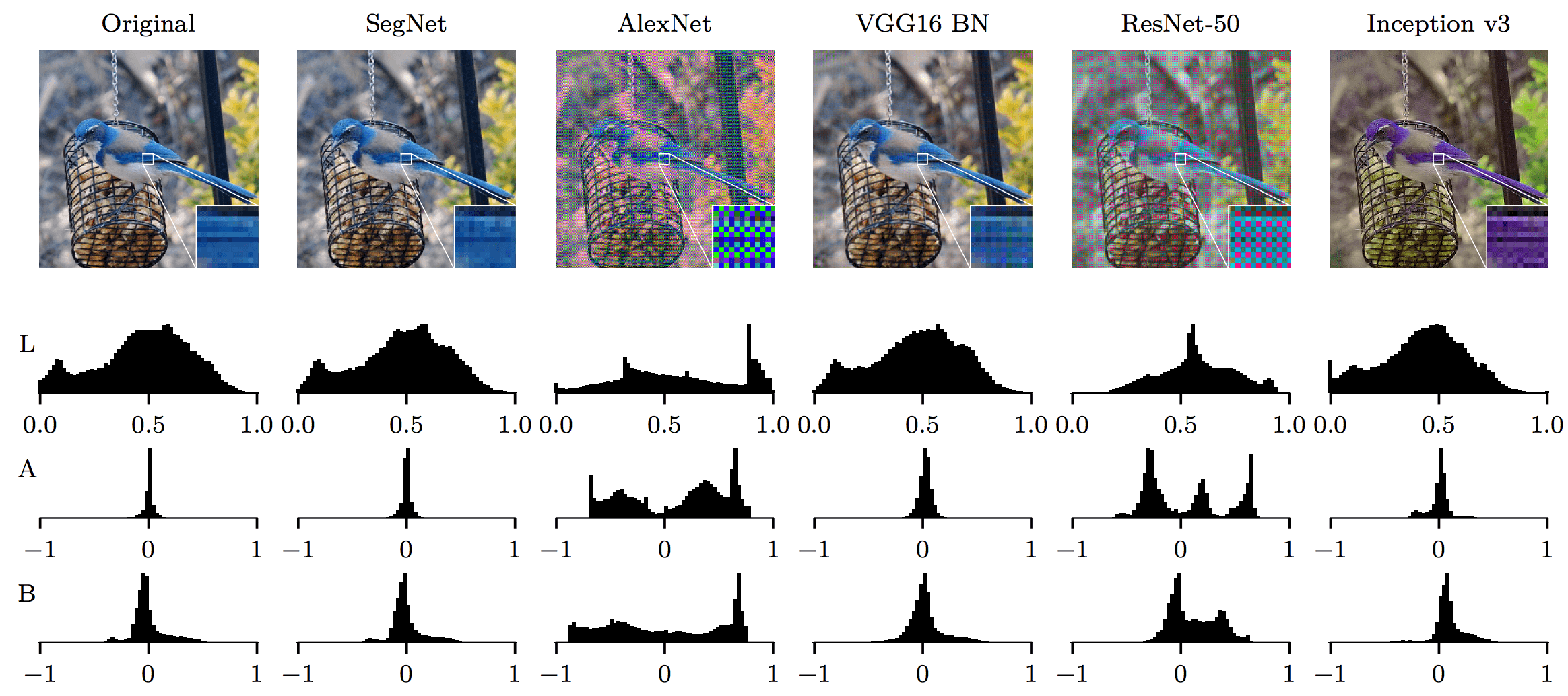
Additional experiments and sample reconstructions
Video summary

Example prototype to reconstruct images using an autoencoder fine-tuned on ResNet50.
This work was supported by the BMBF project DeFuseNN (Grant 01IW17002) and the NVIDIA AI Lab (NVAIL) program.
We would like to express our special gratitude to Adrian Ulges, Christian Schulze and all members at the DLCC for their comments and support.